
이 글에서는 항상 모니터링 해야하는 중요한 메트릭은 어느 것인지, 그에 대해 어떻게 대응해야 하는지에 대해 알아볼 예정이다.
크게 브로커, 프로듀서, 컨슈머에서 각각 중요한 메트릭 정보가 나올 것이며, 브로커는 다시 토픽, 파티션, 로깅과 같이 3가지 세부항목으로 나누어 좀 더 상세한 메트릭 정보를 제공할 예정이다.
Kafka의 메트릭
카프카의 모든 메트릭은 JMX(Java Management Extensions) 인터페이스를 통해 사용할 수 있다.
외부 모니터링 시스템에서 카프카 메트릭을 사용할 때는, 해당 모니터링 시스템의 모니터링 에이전트를 카프카 프로세스에 연결하는 것이 가장 쉬운 방법이다.
카프카 브로커의 JMX에 직접 연결하는 애플리케이션을 도와주기 위해 주키퍼에 저장된 브로커 정보에는 JMX포트가 설정되어 있다.
저장된 위치는 주키퍼의 /brokers/ids/<브로커 ID> 이며, hostname, jmx_port 값이 json 데이터에 포함되어 있다.
브로커 메트릭
| 메트릭 | 정의 | |
| 장애 판단 | 주요 원인 및 대응방안 | |
| UnderReplicatedPartitions (미복제 파티션 갯수) |
브로커 메트릭 중 가장 중요한 메트릭 정보 리더 리플리카 브로커의 파티션을 팔로어 리플리카 브로커들이 복제하지 못한 파티션들의 총계를 제공함 |
|
| 0이 아닌 숫자가 변동없이 꾸준히 나타나는 경우 | - 클러스터의 부하 불균형(kafka-reassign-partition.sh를 이용한 재할당 추천) - 리소스 자원 고갈(CPU, 네트워크 처리량, 디스크) - 하드웨어 장애 - 다른 프로세스와의 충돌 - 로컬 구성의 차이(다른 브로커와 비교해볼것) |
|
| ActiveControllerCount | 해당 브로커가 클러스터의 컨트롤러인지를 나타내는 정보 값은 0 또는 1을 갖는다. 컨트롤러인 경우 1의 값을 갖는다 |
|
| 1의 값을 갖는 브로커가 2개 이상인 경우 1의 값을 갖는 브로커가 한개도 없는 경우 |
- 컨트롤러가 2개인 경우, 두 브로커 모두 재시작 - 컨트롤러가 없는 경우, 컨트롤러 스레드가 제대로 동작하지 않는 이유 찾아야함(클러스터의 모든 브로커 재시작 권장) |
|
| RequestHandlerAvgIdlePercent (요청 핸들러 유휴 비율) |
요청 핸들러가 사용중이 아닌 시간의 백분율(%)을 나타낸다 실수면서 0과 1사이의 값을 갖는다 |
|
| 이 숫자가 작을수록 브로커의 작업 부담이 커짐 20%미만 - 잠재적인 문제 있음으로 판단 10%미만 - 성능 문제가 진행중임 |
- 스레드 풀의 스레드 수가 충분하지 않은 경우 - 스레드들이 각 요청의 불필요한 작업을 수행하는 경우 |
|
| BytesInPerSec (모든 토픽의 바이트 입력) |
모든 토픽의 바이트 입력을 초당 바이트로 나타낸다 프로듀서로부터 브로커가 받는 메시지 트래픽이 얼마나 되는지 측정하는데 유용하다 클러스터를 확장해야하거나, 데이터 증가에 따른 다른작업을 해야할 시기를 결정하는데 도움을 준다. 클러스터의 파티션들을 리밸런싱 해야하는지 평가할 때 우용하다 |
|
| BytesOutPerSec (모든 토픽의 바이트 출력) |
모든 토픽의 바이트 출력을 초당 바이트로 나타낸다. 이 메트릭은 컨슈머가 메세지를 읽는 속도를 보여준다. 단, 리플리카 트랙픽도 포함한다. 예를들어 복제팩터 2인 경우, 바이트 출력 속도는 바이트 입력속도의 두 배가 된다. |
|
| MessagesInPerSec (모든 토픽의 메세지 입력) |
메세지 크기와 무관하게 초당 입력되는 개별적인 메세지 수를 나타낸다 평균 메시지 크기를 결정하기 위해 바이트 입력 속도와 함께 사용될 수 있다. |
|
| PartitionCount | 브로커가 갖는 모든 리플리카 파티션을 포함한 파티션 갯수를 나타낸다 | |
| LeaderCount |
브로커가 현재 리더인 파티션의 수를 보여준다 클러스터의 모든 브로커에 걸쳐 균등해야 한다. 정기적으로 확인하고 경계할 것 권장 |
|
| 이 메트릭 값이 모든 브로커가 균등하지 않을 때 이 값이 0이 될 때 |
클러스터에 불균형이 발생할 때 브로커드의 리더 갯수가 서로 달라질 수 있다. 0인 경우에는 선호 리플리카 선출을 통해 균형을 맞추어야 한다 |
|
| OfflinePartitionsCount |
클러스터에서 현재 리더가 없는 파티션 개수를 나타낸다 클러스터의 컨트롤러 브로커에 의해서만 제공된다. 프로듀서에게 메시지 유실등의 영향을 줄 수 있으므로 즉시 해결해야 한다 |
|
| 1이상의 경우 | - 해당 파티셔의 리더나 팔로어인 모든 브로커들이 다운되었을 때 - 해당 파티션의 리더와 팔로어간의 메세지 개수 불일치로 인해 리더가 될 수 있는 동기화 리플리카가 없고 언클린 리더 선출이 비활성화 되어있을 때 |
|
토픽 메트릭
모든 토픽 메트릭의 측정치는 브로커 메트릭과 매우 유사하다. 토픽 이름이 지정된다는 것과 지정된 토픽에만 각 메트릭이 국한된다는 점이 다르다.
| 이름 | JMX MBean |
| 바이트 입력 | kafka.srver:type=BorkerTopicMetrics, name=BytesInPerSec, topic=TOPICNAME |
| 바이트 출력 | kafka.srver:type=BorkerTopicMetrics, name=BytesOutPerSec, topic=TOPICNAME |
| 읽기 실패 요청 수 | kafka.srver:type=BorkerTopicMetrics, name=FailedFetchRequestsPerSec, topic=TOPICNAME |
| 쓰기 실패 요청 수 | kafka.srver:type=BorkerTopicMetrics, name=FailedProduceRequestsPerSec, topic=TOPICNAME |
| 입력 메시지 수 | kafka.srver:type=BorkerTopicMetrics, name=MessageInPerSec, topic=TOPICNAME |
| 전체 읽기 요청 수 | kafka.srver:type=BorkerTopicMetrics, name=TotalFetchRequestsPerSec, topic=TOPICNAME |
| 전체 쓰기 요청 수 | kafka.srver:type=BorkerTopicMetrics, name=TotalProduceRequestsPerSec, topic=TOPICNAME |
파티션 메트릭
지속적으로 사용하는 관점에서는 파티션 메트릭이 토픽 메트릭에 비해 덜 유용한 편이다. 그러나 파티션 메트릭은 일부 제한된 상황에서 유용할 수 있다.(파티션 크기 측정 및 자원 추적 관리에 유용)
| 이름 | JMX MBean |
| 파티션 크기 | kafka.log:type=Log, name=Size, topic=TOPICNAME, partition=2 |
| 로그 세그먼트 갯수 | kafka.log:type=Log, name=NumLogSegments, topic=TOPICNAME, partition=2 |
| 로그 끝 오프셋 | kafka.log:type=Log, name=LogEndOffset, topic=TOPICNAME, partition=2 |
| 로그 시작 오프셋 | kafka.log:type=Log, name=LogStartOffset, topic=TOPICNAME, partition=2 |
그 외 GC 모니터링, OS 모니터링 등이 존재하나.. 필요시에 찾아보는 것으로..
로깅
| 로거 | 로깅 내용 |
| kafka.controller | INFO 레벨로 로깅 - 토픽 생성과 변경 - 브로커 상태 변경 - 클러스터 자체 작업(선호 리플리카 선출, 파티션 재할당) |
| kafka.server.ClientQuotaManager | INFO 레벨로 로깅 프로듀서와 컨슈머 쿼터 작업과 관련된 메세지 제공 |
| kafka.log.LogCleaner kafka.log.Cleaner Kafka.log.LogCleanerManager |
DEBUG 레벨 - 로그 압축 스레드들의 상태 정보 - 각 파티션에 관한 정보 |
| kafka.request.logger | DEBUG 혹은 TRACE 레벨 - 브로커로 전송되는 모든 요청에 관한 정보 로깅 - 연결 엔드 포인트 - 요청 타이밍 - 요약정보 - 토픽과 파티션 정보 |
프로듀서 메트릭
| 이름 | JMX Mbean |
| 전체 프로듀서 | kafka.producer:type=producer-metrics, clinet-id=CLIENTID 메시지 배치의 크기부터 메모리 버퍼 사용에 대한 속성까지 모두 제공한다. ※ 주의 깊게 봐야할 속성 - record-error-rate : 항상 0 이어야 함. 메세지 전송 실패 시 삭제한 값을 지님 - request-latency-avg : 브로커가 produce 요청 받을 때까지 소요된 평균시간(임계값을 찾을것) 메시지 트래픽 측정 관련 속성 - outgoing-byte-rate : 초당 입력되는 메시지의 절대 크기(바이트) - record-send-rate : 초당 쓰는 메시지 개수 형태로 트래픽을 나타냄 - request-rate : 브로커에게 전송되는 초당 produce 요청 수 제공 메시지 크기 관련 속성 - request-size-avg : 브로커에게 전송되는 produce 요청의 평균 크기(바이트) - batch-size-avg : 한 메시지 배치의 평균 크기(바이트) - record-size-avg : 한 레코드의 평균 크기(바이트) - records-per-request-avg : 하나의 produce 요청에 있는 메시지의 평균 개수 |
| 프로듀서 - 브로커 | kafka.producer:type=producer-node-metrics, clinet-id=CLIENTID 전체 프로듀서 메트릭에 추가하여 특정 상황의 문제점을 디버깅하는데 유용 가장 유용한 메트릭 - request-latency-avg - outgoing-byte-rate - request-latency-avg |
| 프로듀서- 토픽 | kafka.producer:type=producer-topic-metrics, clinet-id=CLIENTID 두 개 이상의 토픽을 사용하는 프로듀서의 경우 프로듀서-브로커 메트릭보다 더 유용함 가장 유용한 메트릭 - record-send-rate - record-error-rate - byte-rate |
컨슈머 메트릭
| 이름 | JMX Mbean |
| 전체 컨슈머 | kafka.consumer:type=consumer-metrics, client-id=CLIENTID |
| Fetch 매니저 | kafka.consumer:type=consumer-fetch-manager-metrics, client-id=CLIENTID 컨슈머에서는 Fetch 매니저가 전체 컨슈머 메트릭보다 더 중요한 메트릭들을 들고 있다 가장 유용한 메트릭 - fetch-latency-avg : fetch 요청을 브로커가 받는 데 걸리는 시간 - bytes-consumed-rate : 컨슈머가 처리하는 메시지 트래픽 측정시 사용 - records-consumed-rate : 컨슈머가 처리하는 메시지 트래픽 측정시 사용 - fetch-rate : 컨슈머가 수행하는 초당 fetch 요청 수 - fetch-size-avg : 각 fetch 요청의 평균 크기를 제공 - records-per-request-avg : 각 fetch 요청의 평균 메시지 수 |
| 컨슈머 - 토픽 | kafka.consumer:type=consumer-fetch-manager-metrics, client-id=CLIENTID, topic=TOPICNAME |
| 컨슈머 - 브로커 | kafka.consumer:type=consumer-node-metrics, client-id=CLIENTID, node id=node-BROKERID 가장 유용한 메트릭 - request-latency-avg - incoming-byte-rate - request-rate |
| 컨슈머 - 조정자 | kafka.consumer:type=consumer-cordinator-metrics, client-id=CLIENTID |
그 외 컨슈머 지연 모니터링, end-to-end 모니터링은 외부 모니터링 시스템을 사용해서 수행할 수 있다.
참고 - https://docs.confluent.io/platform/current/kafka/monitoring.html#
kafka-lag-dashboard
Kafka lag을 모니터링하는 확실한 방법
Kafka Consumer의 처리시간이 지연되면 topic 내부의 partition lag이 증가합니다. lag 모니터링을 통해 어느 partition이 lag이 증가하고 있는지, 어느 컨슈머가 문제가 있는지 확인하기 위해서는 consumer단위의 metric 모니터링으로는 해결하기 쉽지 않습니다. 그렇기 때문에 카프카 컨슈머 모니터링을 위해서는 burrow와 같은 외부 모니터링 tool 사용을 권장합니다.

이 문서에서는 Linkedin에서 제공한 burrow를 사용하여 lag정보를 Elasticsearch로 수집하는 데이터파이프라인을 만들어보고, Grafana 기반의 consumer단위 lag 모니터링 대시보드를 만드는 방법을 알려드리고자 합니다. 또한 lag증가에 따른 Slack alert를 받는 기능도 구현해보도록 하겠습니다.
준비물
Partition lag을 모니터링하고 alert를 받기 위해 아래와 같은 기술 stack을 사용합니다. 아래 기술 stack은 무료로 사용 가능하면서도 필요한기능들(alert, pipeline 등)을 효과적으로 적용가능하기 때문에 고르게 되었습니다. 필요에 따라 기술을 대체할 수 있으므로, 요구사항에 따라 바꿔 사용하셔도 좋습니다. (예를 들어, Grafana → Elasticsearch X-Pack)
- Burrow(link) : linkedin에서 공개한 opensource lag monitoring application입니다. rest api를 통해 lag 정보를 전달받을 수 있습니다.
- Telegraf(link) : 데이터의 수집 및 전달에 특화된 agent입니다. configuration설정을 통해 burrow의 데이터를 ES에 넣는 역할을 합니다.
- Elasticsearch(link) : kafka lag 데이터를 저장하는 역할을 합니다.
- Grafana(link) : ES의 데이터를 시각화하고 threshold를 설정하여 slack alert를 보낼 수 있는 강력한 대시보드 tool입니다.
준비물의 설치 방법 및 사용방법은 이 문서에서 다루지 않습니다. 상세 내용은 각 기술 document를 참고해주세요.
설정
1) Burrow 설정
Burrow는 kafka 클러스터와 연동되어 lag정보를 rest api를 통해 조회할 수 있습니다. Burrow 그 자체로도 alert를 보낼 수 있는 기능이 제공되지만 장기적으로 봤을 때 데이터가 쌓이지 않기 때문에 alert이전 내용에 대한 분석이 매우 어렵습니다. 이 문서에서는 burrow에서 수집한 데이터를 Elasticsearch에 적재할 예정이므로, burrow설정에서는 기본적인 kafka와의 연동만 하도록 합니다.
만약 kafka가 SASL 등의 보안정책을 가지고 있거나 추가 설정이 필요하신 분은 이 링크를 참고하시기 바랍니다.
burrow.toml
[zookeeper]
servers=["주키퍼01:2181","주키퍼02:2181","주키퍼03:2181"]
timeout=6
root-path="/burrow"
[cluster.live]
class-name="kafka"
servers=["카프카01:9092","카프카02:9092","카프카03:9092"]
topic-refresh=120
offset-refresh=30
[consumer.live]
class-name="kafka"
cluster="live"
servers=["카프카01:9092","카프카02:9092","카프카03:9092"]
group-blacklist="^(console-consumer-|quick-).*$"
group-whitelist=""
[consumer.live_zk]
class-name="kafka_zk"
cluster="live"
servers=["주키퍼01:2181","주키퍼02:2181","주키퍼03:2181"]
zookeeper-timeout=30
group-blacklist="^(console-consumer-|quick-).*$"
group-whitelist=""
[httpserver.default]
address=":8000"
2) Telegraf 설정
Telegraf는 agent application으로서 burrow의 rest api데이터를 일정주기로 ES에 전달하는 역할을 합니다.
telegraf.conf
[[inputs.burrow]]
servers = ["http://버로우:8000"]
topics_exclude = [ "__consumer_offsets" ]
groups_exclude = ["console-*"]
[[outputs.elasticsearch]]
urls = [ "http://엘라스틱서치:9200" ]
timeout = "5s"
enable_sniffer = false
health_check_interval = "10s"
index_name = "burrow-%Y.%m.%d"
manage_template = false
3) Elasticsearch 설정
Elasticsearch에 수집된 document들의 index pattern을 정의해야합니다. Kibana를 통해 아래와 같이 패턴을 정의할 수 있습니다.
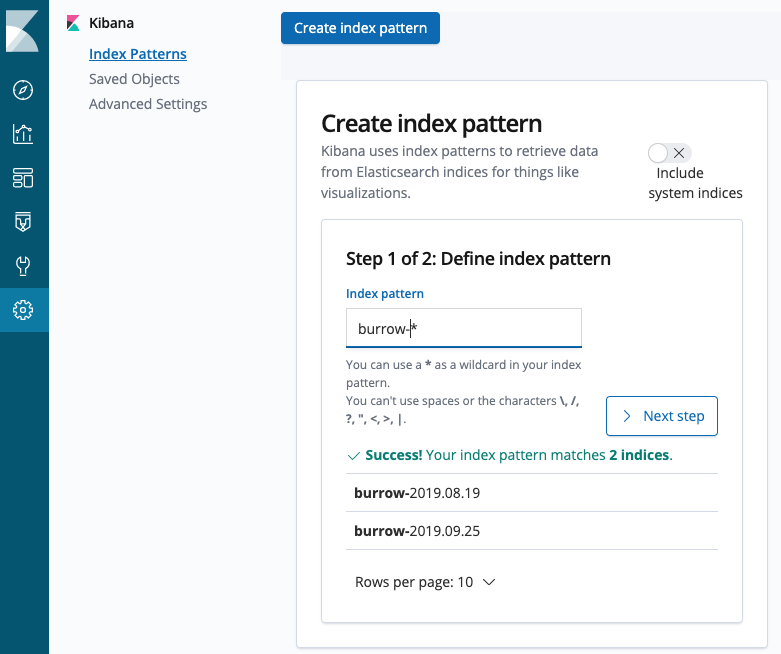
4) Grafana 설정
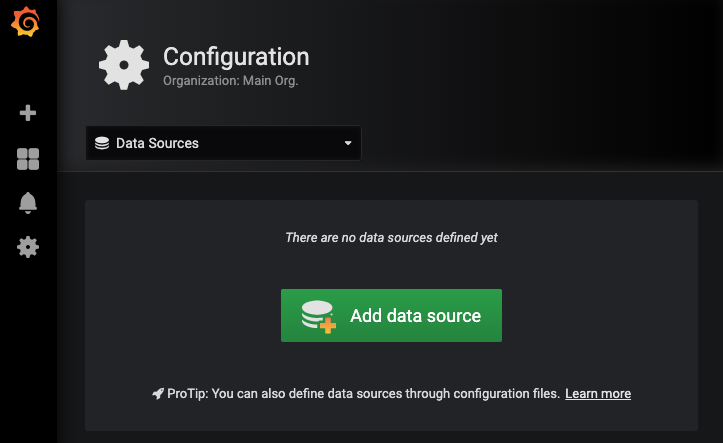
Elasticsearch와 연동을 위해서 아래와 같이 Datasource 연동이 필요합니다.
▶ Grafana Datasorce 추가
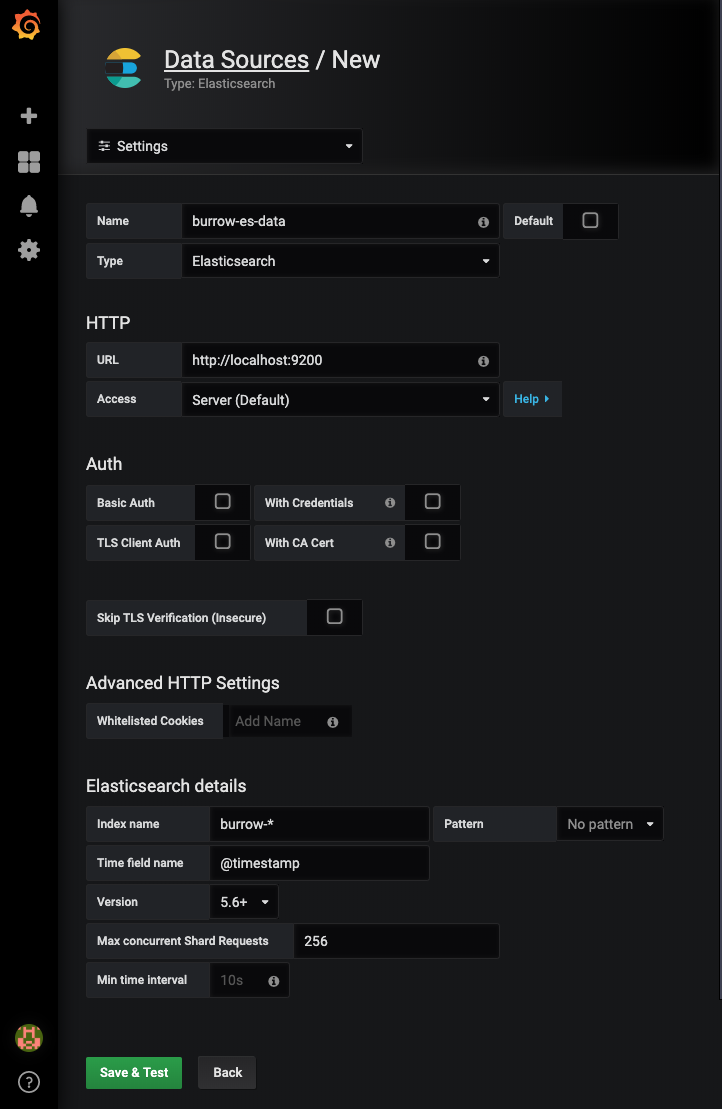
▶ Datasource에 Elasticsearch, index pattern 정보 추가
결과물
Kafka lag 조회
위 설정까지 끝내셨다면 lag을 모니터링할 준비가 완료되었습니다. 이제 Grafana 대시보드에서 그래프를 만들어서 Elasticsearch의 데이터를 기반으로 그래프를 그려보겠습니다.
▶ 그래프 설정
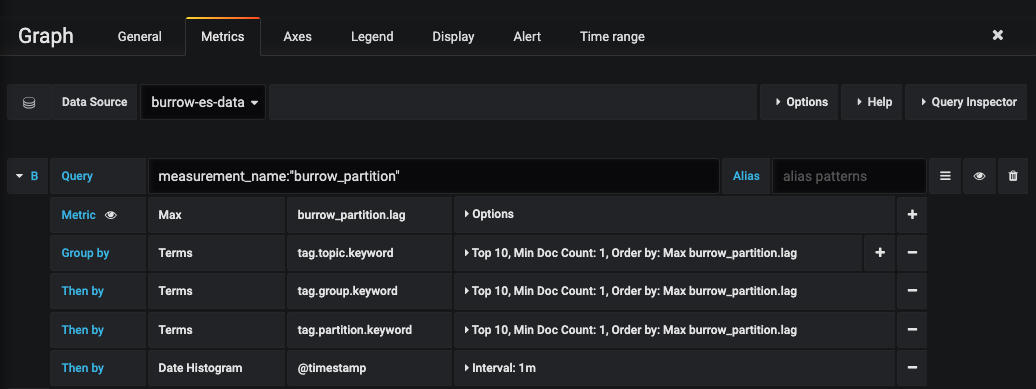
burrow에서 수집한 데이터 중 measure_ment_name이 burrow_partition 인것만 대상으로 lag을 수집합니다. topic, groupId, partition 별로 group by로 묶어주시면 topic, groupId, partition별 lag추이를 확인할 수 있습니다.
▶ 그래프 확인
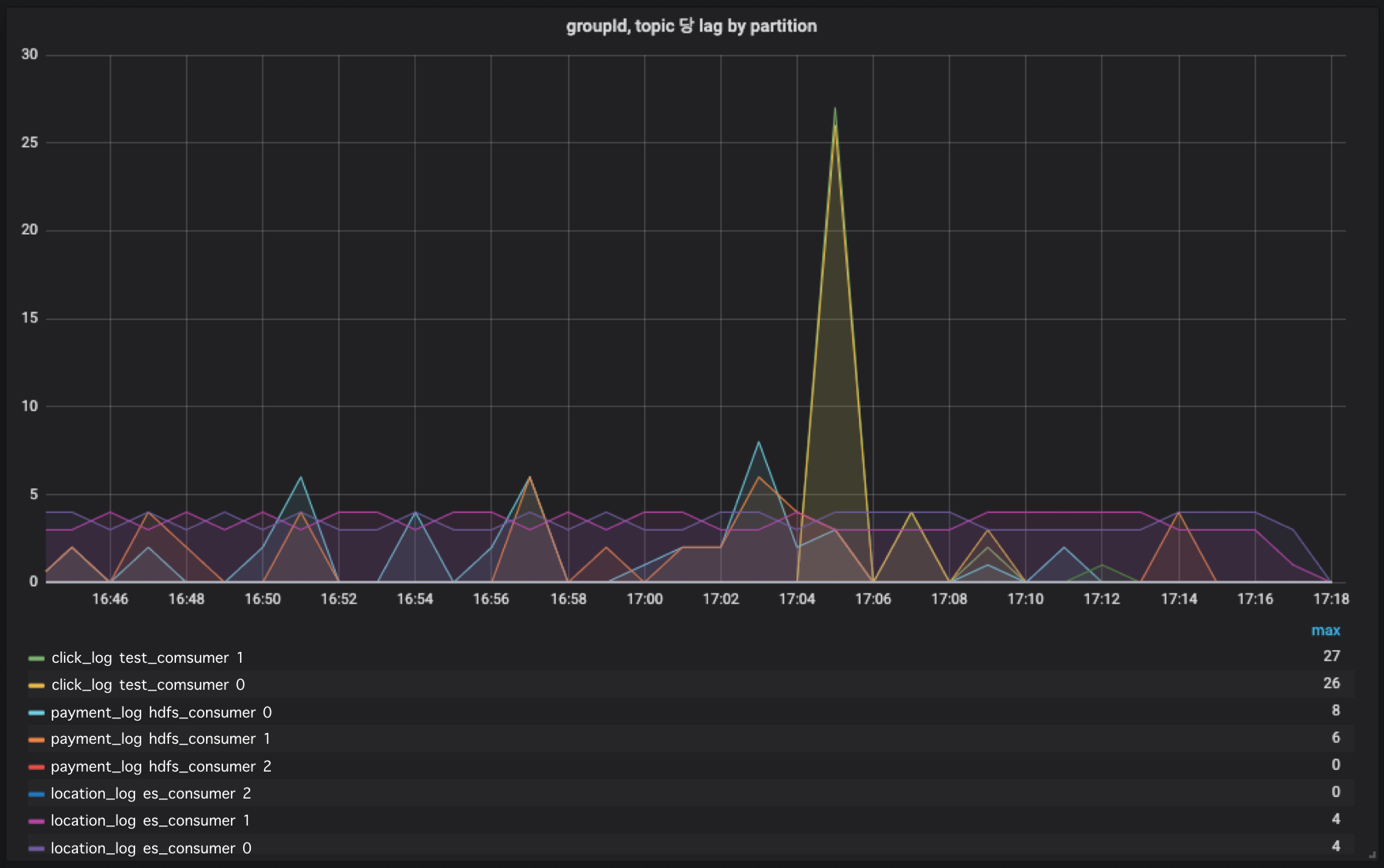
Kakfa lag slack alert 설정
Grafana에는 alert기능이 준비되어 있습니다. Alert는 Slack뿐만아니라 Line, Telegram, webhook, email 등 다양한 방식의 alert를 제공하고 있으므로 필요에 따라 사용하고 싶은 alert를 사용하셔도 좋습니다.
▶ Slack url경로 추가
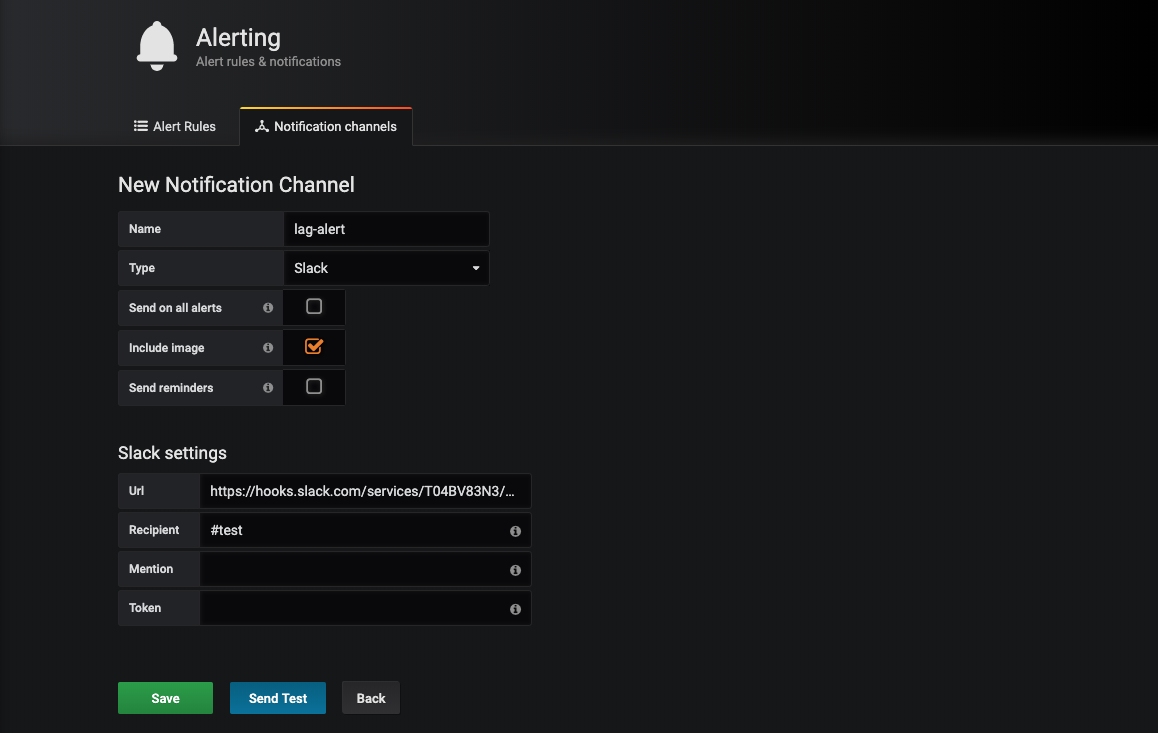
Slack과 연동하기 위해서는 url을 발급받아야 합니다. webhook url을 발급받는 방법은 이 링크를 확인해주세요.
▶ 그래프 alert 설정
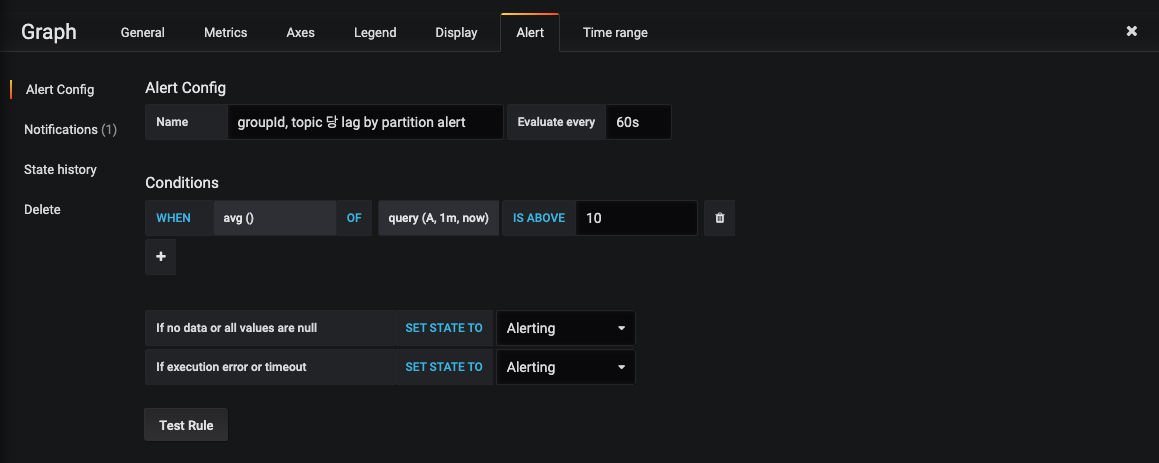
Alert를 받고 싶은 그래프에서 Alert configuration을 추가합니다. 위 쿼리는 1분마다, 지난 60초간 lag의 평균값이 10 이상일 경우에 Slack 메시지를 보내도록 설정하였습니다. 필요에 따라 설정을 변경하여 적용하면 lag 모니터링시 유용합니다.
▶ 이상징후 발생
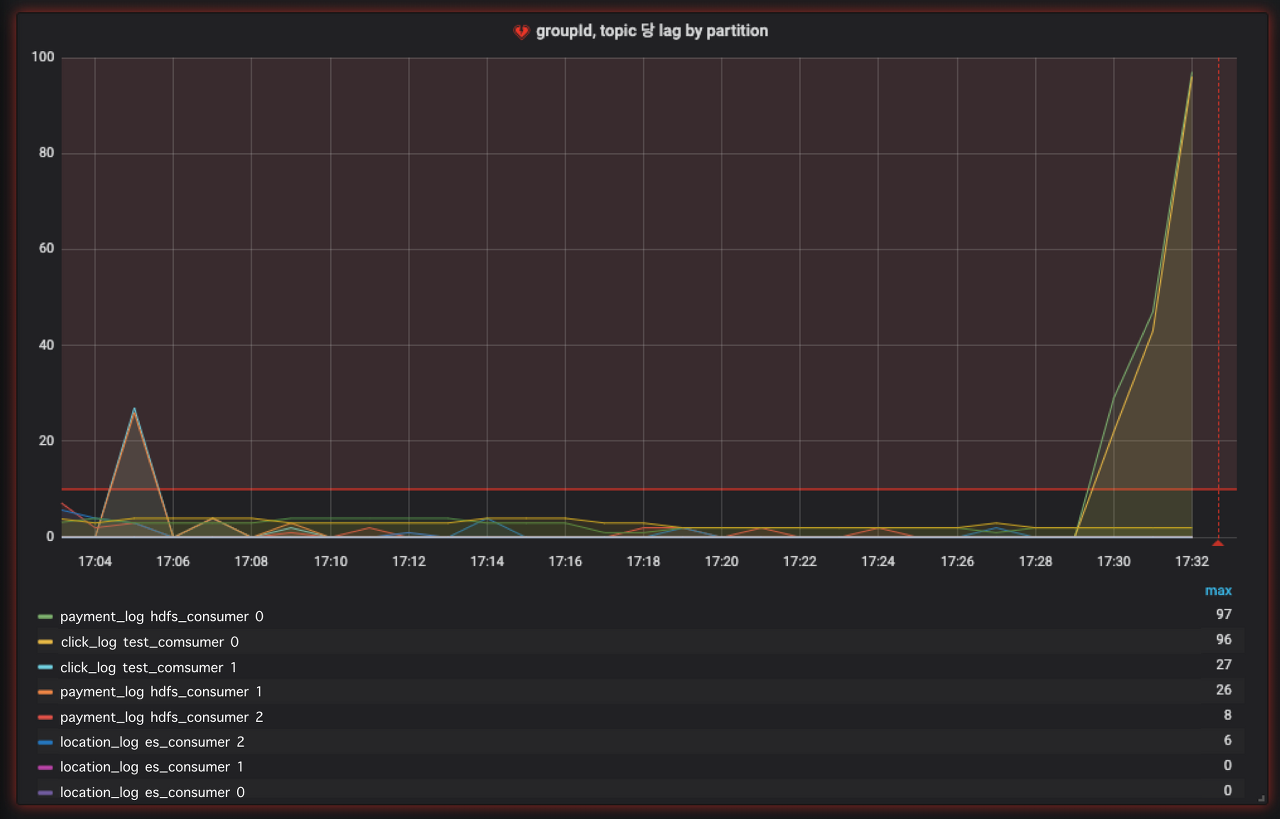
이상징후가 발생하면 그래프에서도 빨강색으로 표시되어 이상이 생겼음을 한눈에 확인할 수 있습니다.
▶ Slack 메시지 확인
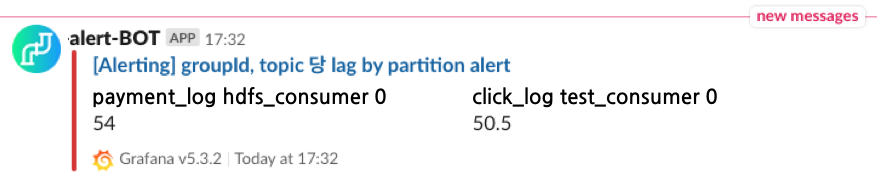
설정한 threshold값을 넘길때 slack을 통해 정상적으로 메시지가 전달되어 알려지는 것을 확인할 수 있습니다.
'Programming > [kafka]' 카테고리의 다른 글
| [kafka] Burrow 설치 및 설정 (0) | 2022.02.14 |
|---|---|
| [kafka] CMAK 설치 및 연동 (0) | 2022.02.14 |
| [kafka] 환경 구축 및 예제 (0) | 2022.01.26 |
| [kafka] Apache kafka (0) | 2022.01.24 |



